
1 Basic Concepts
Statistics is a fundamental field that plays a crucial role in various disciplines, from science and economics to social sciences and beyond. It’s the science of collecting, organizing, analyzing, interpreting, and presenting data. In this introductory overview, we’ll explore some key concepts and ideas that form the foundation of statistics:
Data: At the heart of statistics is data. Data can be anything from numbers and measurements to observations and information collected from experiments, surveys, or observations. In statistical analysis, we work with two main types of data: quantitative (numerical) and qualitative (categorical).
Descriptive Statistics: Descriptive statistics involve methods for summarizing and organizing data. These methods help us understand the basic characteristics of data, such as measures of central tendency (mean, median, mode) and measures of variability (range, variance, standard deviation).
Inferential Statistics: Inferential statistics is about making predictions, inferences, or decisions about a population based on a sample of data. This involves hypothesis testing, confidence intervals, and regression analysis, among other techniques.
Probability: Probability theory is the foundation of statistics. It deals with uncertainty and randomness. We use probability to describe the likelihood of events occurring in various situations, which is essential for making statistical inferences.
Sampling: In most cases, it’s impractical to collect data from an entire population. Instead, we often work with samples, which are smaller subsets of the population. The process of selecting and analyzing samples is a critical aspect of statistical analysis.
Variables: Variables are characteristics or attributes that can vary from one individual or item to another. They can be categorized as dependent (response) or independent (predictor) variables, depending on their role in a statistical analysis.
Distributions: A probability distribution describes the possible values of a variable and their associated probabilities. Common distributions include the normal distribution, binomial distribution, and Poisson distribution, among others.
Statistical Software: In the modern era, statistical analysis is often conducted using specialized software packages like R, Python (with libraries like NumPy and Pandas), SPSS, or Excel. These tools facilitate data manipulation, visualization, and complex statistical calculations.
Ethics and Bias: It’s essential to consider ethical principles in statistical analysis, including issues related to data privacy, confidentiality, and the potential for bias in data collection and interpretation.
Real-World Applications: Statistics has a wide range of applications, from medical research to marketing, finance, and social sciences. It helps us make informed decisions and draw meaningful insights from data in various fields.
1.1 Probability
1.1.1 Overview
Probability theory is a fundamental concept in the field of statistics, serving as the foundation upon which many statistical methods and models are built.
1.1.2 What is Probability?
Probability is a mathematical concept that quantifies the uncertainty or randomness of events. It provides a way to measure the likelihood of different outcomes occurring in a given situation. In essence, probability is a numerical representation of our uncertainty.
1.1.3 Basic Probability Terminology
Experiment: An experiment is any process or procedure that results in an outcome. For example, rolling a fair six-sided die is an experiment.
Outcome: An outcome is a possible result of an experiment. When rolling a die, the outcomes are the numbers 1 through 6.
Sample Space (S): The sample space is the set of all possible outcomes of an experiment. For a fair six-sided die, the sample space is \(\{1, 2, 3, 4, 5, 6\}\).
Event (E): An event is a specific subset of the sample space. It represents a particular set of outcomes that we are interested in. For instance, “rolling an even number” is an event for a six-sided die, which includes outcomes \(\{2, 4, 6\}\).
1.1.4 Probability Notation
In probability theory, we use notation to represent various concepts:
- P(E): Probability of event E occurring.
- P(A and B): Probability of both events A and B occurring.
- P(A or B): Probability of either event A or event B occurring.
- P(E’): Probability of the complement of event E, which is the probability of E not occurring.
1.1.5 The Fundamental Principles of Probability
There are two fundamental principles of probability:
- The Addition Rule: It states that the probability of either event A or event B occurring is given by the sum of their individual probabilities, provided that the events are mutually exclusive (i.e., they cannot both occur simultaneously).
\[\begin{align} P(A \; or \; B) = P(A) + P(B) \end{align}\]
- The Multiplication Rule: It states that the probability of both event A and event B occurring is the product of their individual probabilities, provided that the events are independent (i.e., the occurrence of one event does not affect the occurrence of the other).
\[\begin{align} P(A \; and\;B) = P(A) * P(B) \end{align}\]
1.1.6 Example: Rolling a Fair Six-Sided Die
Consider rolling a fair six-sided die.
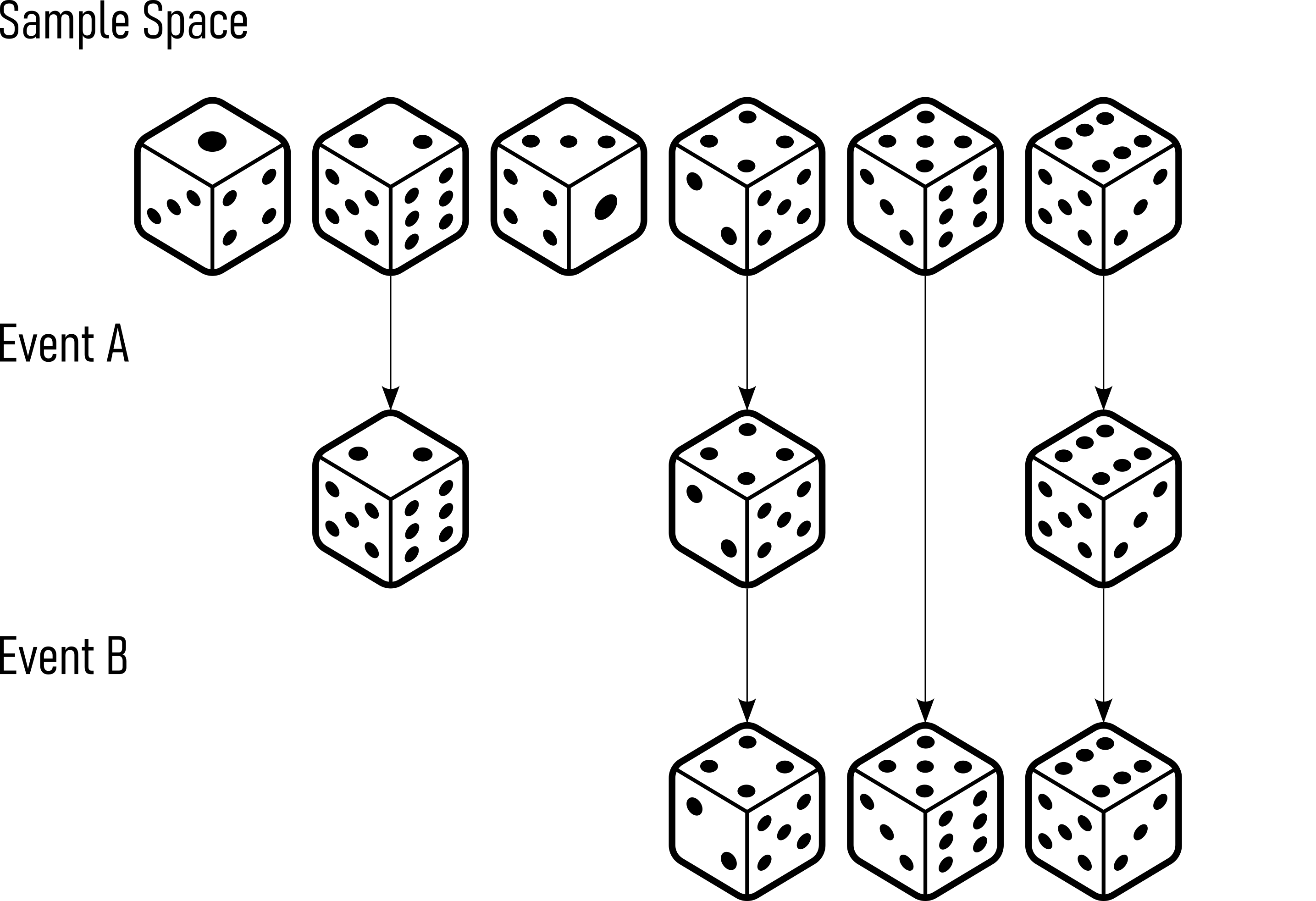
- Sample Space (S): \(\{1, 2, 3, 4, 5, 6\}\) (Figure 1.1)
- Event A: Rolling an even number = \(\{2, 4, 6\}\) (Figure 1.1)
- Event B: Rolling a number greater than \(3 = \{4, 5, 6\}\) (Figure 1.1)
1.1.7 Probability in action - The Galton Board
A Galton board, also known as a bean machine or a quincunx, is a mechanical device that demonstrates the principles of probability and the normal distribution. It was invented by Sir Francis Galton1 in the late 19th century. The Galton board consists of a vertical board with a series of pegs or nails arranged in triangular or hexagonal patterns.
A Galton board, also known as a bean machine or a quincunx, is a mechanical device that demonstrates the principles of probability and the normal distribution. It was invented by Sir Francis Galton in the late 19th century. The Galton board consists of a vertical board with a series of pegs or nails arranged in triangular or hexagonal patterns.
Initial Release: At the top of the Galton board, a ball or particle is released. This ball can take one of two paths at each peg, either to the left or to the right. The decision at each peg is determined by chance, such as the flip of a coin or the roll of a die. This represents a random event.
Multiple Trials: As the ball progresses downward, it encounters several pegs, each of which randomly directs it either left or right. The ball continues to bounce off pegs until it reaches the bottom.
Accumulation: Over multiple trials or runs of the Galton board, you will notice that the balls accumulate in a pattern at the bottom. This pattern forms a bell-shaped curve, which is the hallmark of a normal distribution.
Normal Distribution: The accumulation of balls at the bottom resembles the shape of a normal distribution curve. This means that the majority of balls will tend to accumulate in the center, forming the peak of the curve, while fewer balls will accumulate at the extreme left and right sides.
The Galton board is a visual representation of the central limit theorem, a fundamental concept in probability theory. It demonstrates how random events, when repeated many times, tend to follow a normal distribution. This distribution is commonly observed in various natural phenomena and is essential in statistical analysis.

1.1.7.1 Statistics and Probabbility
The Galton board is a nice example how statistics emerge from probability.
1.1.7.1.1 Define the problem
- The board has \(n\) rows of pegs (columns)
- Each ball has an equal probability of moving left or right (assuming no bias)
- The number of rightward moves determines the final position in the bins
1.1.7.1.2 Step 2: Binomial Probability Distribution
Each ball independently moves right (\(R\)) or left (\(L\)) with a probability of \(p=0.5\).
The number of rightwards moves follows a binomial distribution.
\[\begin{align} P(k) = \binom{n}{k} p^k (1 - p)^{n - k} \end{align}\]
- \(n\)
- total number of columns (or pegs encountered)
- \(k\)
- number of rightward moves
- \(\binom{n}{k}\)
- biomial coefficient, given by \(\binom{n}{k} = \frac{n!}{k!(n-k)!}\)
with \(p = 0.5\) this simplifies to
\[\begin{align} P(k) = \binom{n}{k} ( \frac{1}{2})^n \end{align}\]
1.1.7.1.3 Step 3: Position Mapping
The final position of a ball in a bin corresponds to the number of rightwards moves \(k\). If the bins are indexed from \(0\) to \(n\) (where \(k=0\) means all left moves and \(k=n\) means all right moves) the probability of landing in bin \(k\) is:
\[\begin{align} P(k) = \frac{n!}{k!(n-k)!}(\frac{1}{2})^n \end{align}\]
1.2 Central Limit Theorem (CLT)
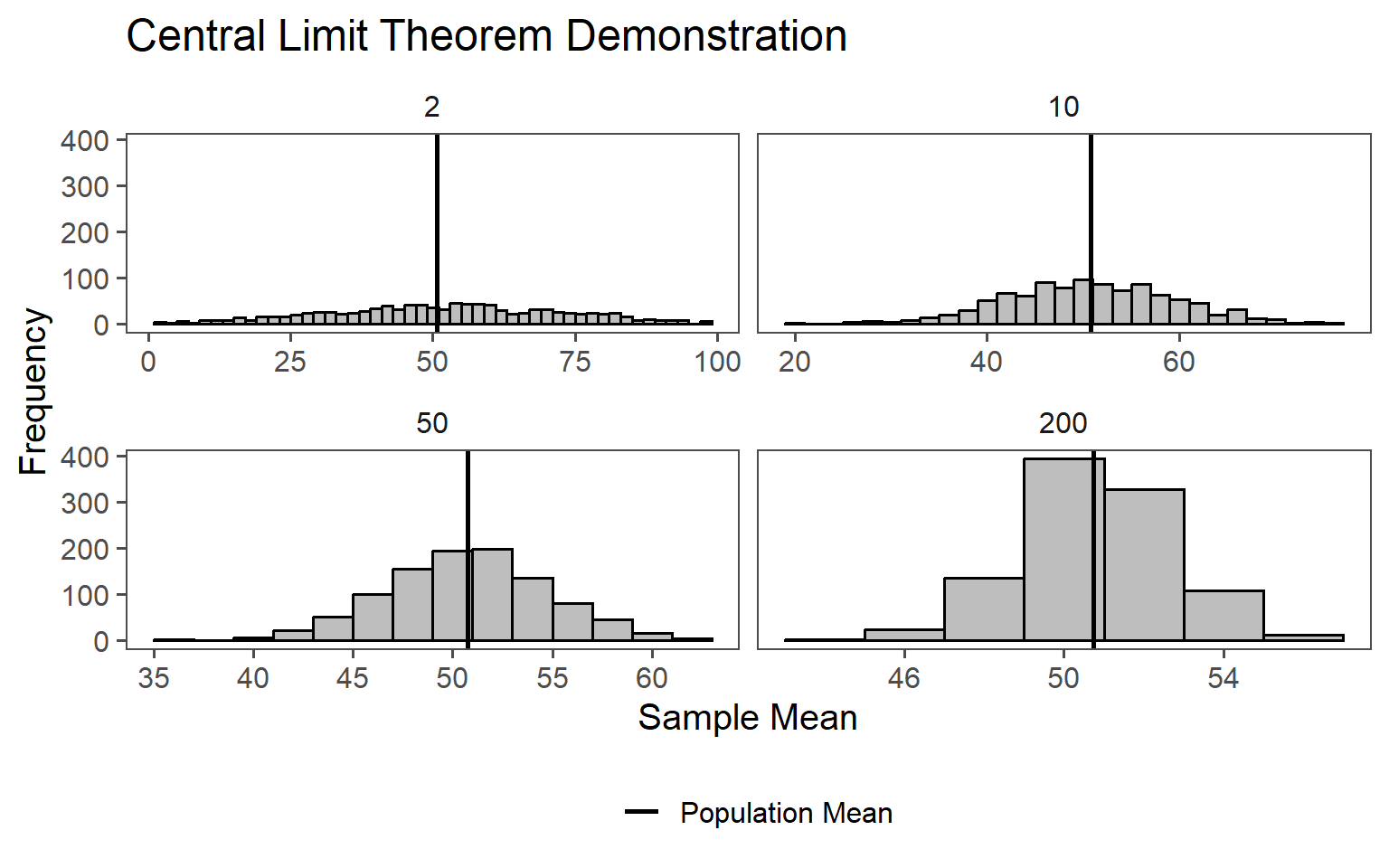
The primary reason for the existence of the normal distribution in many real-world datasets is the CLT (Taboga 2017). The CLT states that when you take a large enough number of random samples from any population, the distribution of the sample means will tend to follow a normal distribution, even if the original population distribution is not normal. This means that the normal distribution emerges as a statistical consequence of aggregating random data points. This is shown in Figure 1.3.
From \(n=10000\) uniformly distributed data points (the population) (\(min=1, max = 100\)) either \(2,10,50\) or \(200\) samples are taken randomly (the samples). For each of the samples the mean is calculated, resulting in \(1000\) mean values for each (\(2,10,50\) or \(200\)) sample size. In Figure 1.3 the results from this numerical study are shown. The larger the sample size, the closer the mean calculated \(\bar{x}\)is to the population mean (\(\mu_0\)). The effect is especially large on the standard deviation, resulting in a smaller standard deviation the larger the sample size is.
1.3 Law of Large Numbers (LLN)
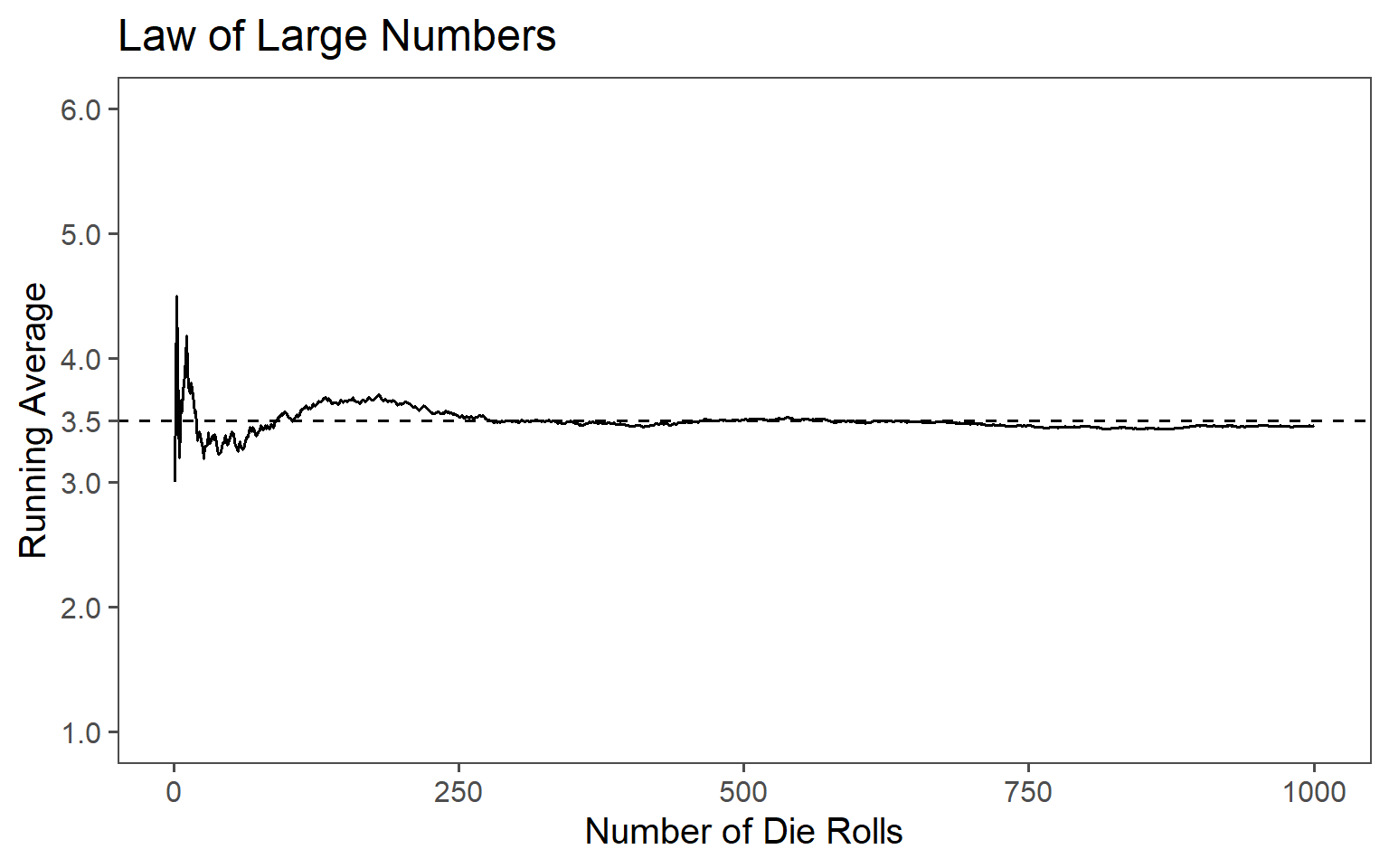
The CLT states that as the size of a random sample increases, the sample average converges to the population mean. This law, along with the CLT, explains why the normal distribution frequently arises. When you take many small, independent, and identically distributed measurements and compute their averages, these averages tend to cluster around the true population mean, forming a normal distribution Johnson (1994).
The LLN ar work is shown in Figure 1.4. A fair six-sided die is rolled 1000 times and the running average of the roll results after each roll is calculated. The resulting line plot shows how the running average approaches the expected value of \(3.5\), which is the average of all possible outcomes of the die. The line in the plot represents the running average It fluctuates at the beginning but gradually converges toward the expected value of \(3.5\). To emphasize this convergence, a dashed line indicating the theoretical expected value which is essentially the expected value applied to each roll. This visualization demonstrates the Law of Large Numbers, which states that as the number of trials or rolls increases, the sample mean (running average in this case) approaches the population mean (expected value) with greater accuracy, showing the predictability and stability of random processes over a large number of observations.
1.4 Population
In statistics, a population is the complete set of individuals, items, or data points that are the subject of a study. Understanding populations and how to work with them is fundamental in statistical analysis, as it forms the basis for making meaningful inferences and drawing conclusions about the broader group being studied. It is the complete collection of all elements that share a common characteristic or feature and is of interest to the researcher. The population can vary widely depending on the research question or problem at hand. A populations true mean is depicted with \(\mu_0\) and the variance is depicted with \(\sigma_0^2\).
1.5 Sample
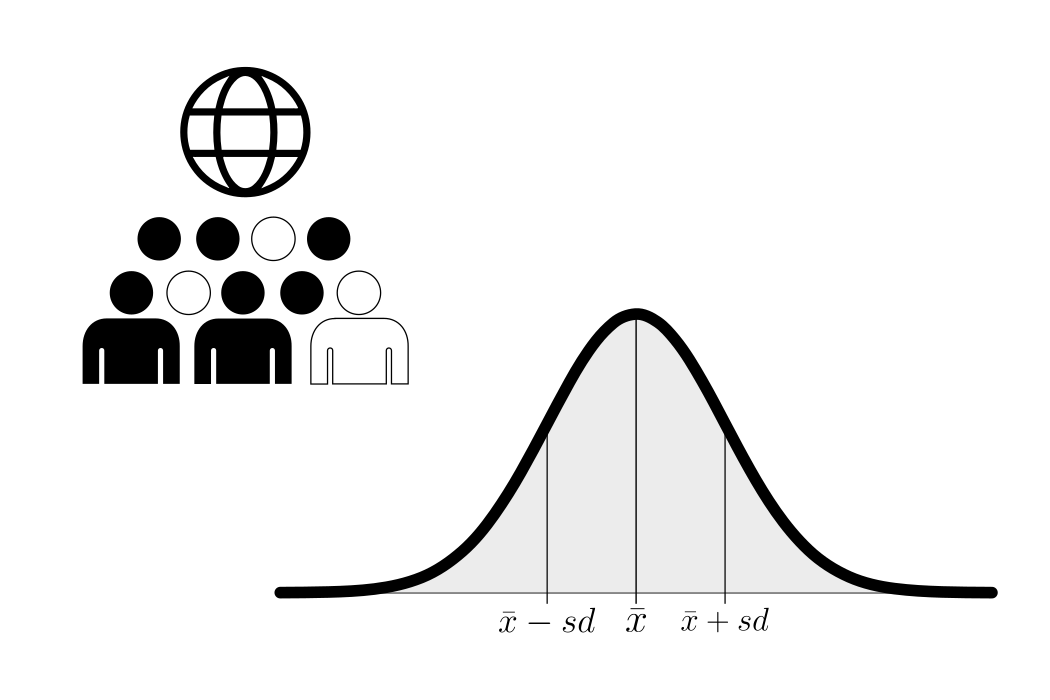
The key principles behind a sample include its role as a manageable subset of data, which can be chosen randomly or purposefully. Ideally, it should be representative, reflecting the characteristics and diversity of the larger population. Statistical techniques are then applied to this sample to make inferences, estimate population parameters, or test hypotheses. The size of the sample matters, as a larger sample often leads to more precise estimates, but it should be determined based on research goals and available resources. Various sampling methods, such as random sampling, stratified sampling, or cluster sampling, can be employed depending on the research objectives and population characteristics. A samples true mean is depicted with \(\bar{x}\) and the variance is depicted with \(sd\).
1.6 Descriptive Statistics
Descriptive statistics are used to summarize and describe the main features of a data set. They provide a way to organize, present, and analyze data in a meaningful and concise manner. Descriptive statistics do not involve making inferences or drawing conclusions beyond the data that is being analyzed. Instead, they aim to provide a clear and accurate representation of the data set. Some common techniques and measures used in descriptive statistics include:
1.6.1 Example Data: The drive shaft exercise

1.6.2 Measures of Central Tendency
Measures of central tendency are essential in statistics because they provide a single value that summarizes or represents the center point or typical value of a dataset. The main reasons for using these measures include:
Simplification of Data: They condense large sets of data into a single representative value, making the data easier to understand and interpret.
Comparison Across Datasets: They allow for straightforward comparison between different groups or datasets by providing a common reference point.
Foundation for Further Analysis: Many statistical techniques and models rely on an understanding of central tendency as a starting point, such as in regression analysis or hypothesis testing.
Decision-Making: In fields such as economics, education, and public policy, central tendency helps inform decisions based on typical outcomes or behaviors (e.g., average income, median test scores).
Identification of Patterns: They help identify patterns and trends over time, especially in time-series data or longitudinal studies.
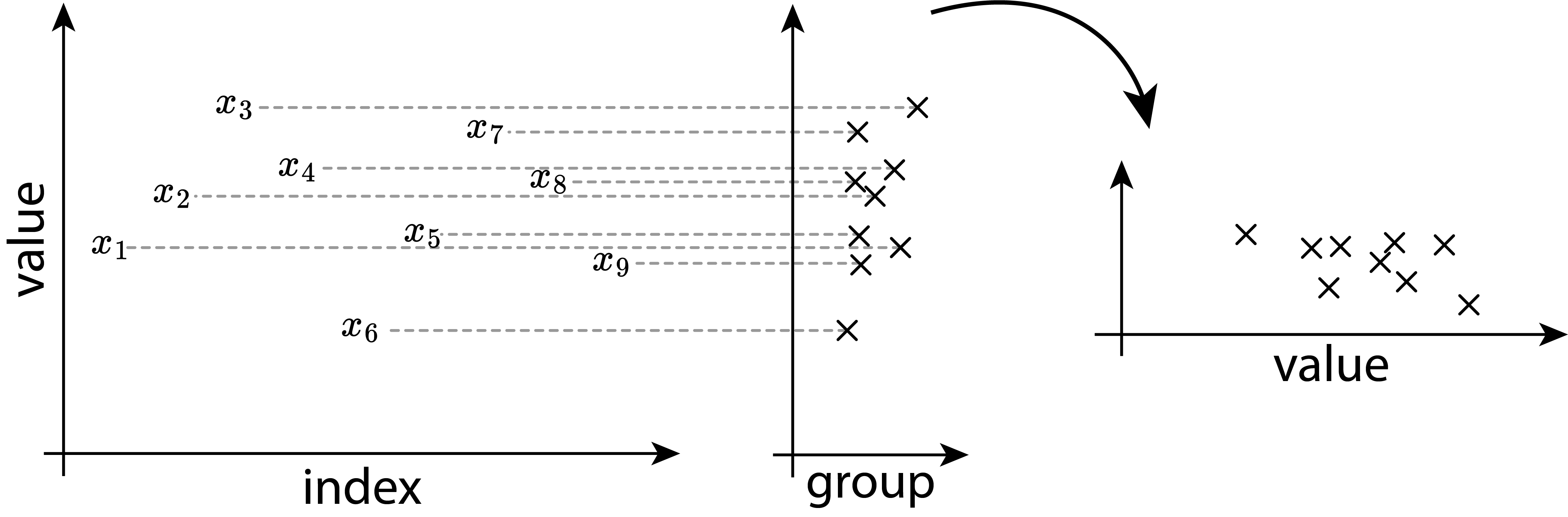
1.6.2.1 Mean

\[\begin{align} \text{discrete: } \mu = \mathbb{E}[X] &= \sum_{i=1}^{n} x_i \, p_i \\ \text{continous: }\mu = \mathbb{E}[X] &= \int_{-\infty}^{\infty} x \, f(x) \, dx \end{align}\]
\[\begin{align} \text{population:} \; \mu &= \frac{1}{N}\sum_i^{N} x_i \\ \text{sample:} \; \bar{x} &= \frac{1}{n}\sum_i^{n} x_i \end{align}\]
1.6.2.2 Median

\[\begin{align} \text{population:} \; m &= \begin{cases} x_{\left(\frac{N+1}{2}\right)} & \text{if } N \text{ is odd} \\ \frac{1}{2} \left( x_{\left(\frac{N}{2}\right)} + x_{\left(\frac{N}{2} + 1\right)} \right) & \text{if } N \text{ is even} \end{cases} \\ \text{sample:} \; \tilde{x} &= \begin{cases} x_{\left(\frac{n+1}{2}\right)} & \text{if } n \text{ is odd} \\ \frac{1}{2} \left( x_{\left(\frac{n}{2}\right)} + x_{\left(\frac{n}{2} + 1\right)} \right) & \text{if } n \text{ is even} \end{cases} \end{align}\]
1.6.3 Measures of Spread

Measures of spread (also called measures of dispersion or variability) are essential in statistics to provide information about the distribution of data — specifically, how much the data values differ from each other and from the central tendency.
Contextualizing Central Tendency: The mean or median alone does not give a complete picture of the data. Two datasets can have the same mean but very different spreads.
Understanding Data Consistency: Measures of spread indicate how consistent or reliable the data are. A small spread suggests the values are closely clustered around the mean, while a large spread indicates greater variability and less predictability.
Identifying Outliers: Large measures of spread may indicate the presence of outliers — values that are significantly different from others in the dataset. This can be important in quality control, risk assessment, and anomaly detection.
Comparing Distributions: Spread allows for meaningful comparison between different datasets.
Informing Statistical Models: Many statistical methods, such as regression, hypothesis testing, and confidence intervals, rely on measures of spread (like variance or standard deviation) to estimate error, assess significance, or make predictions.
1.6.3.1 Range
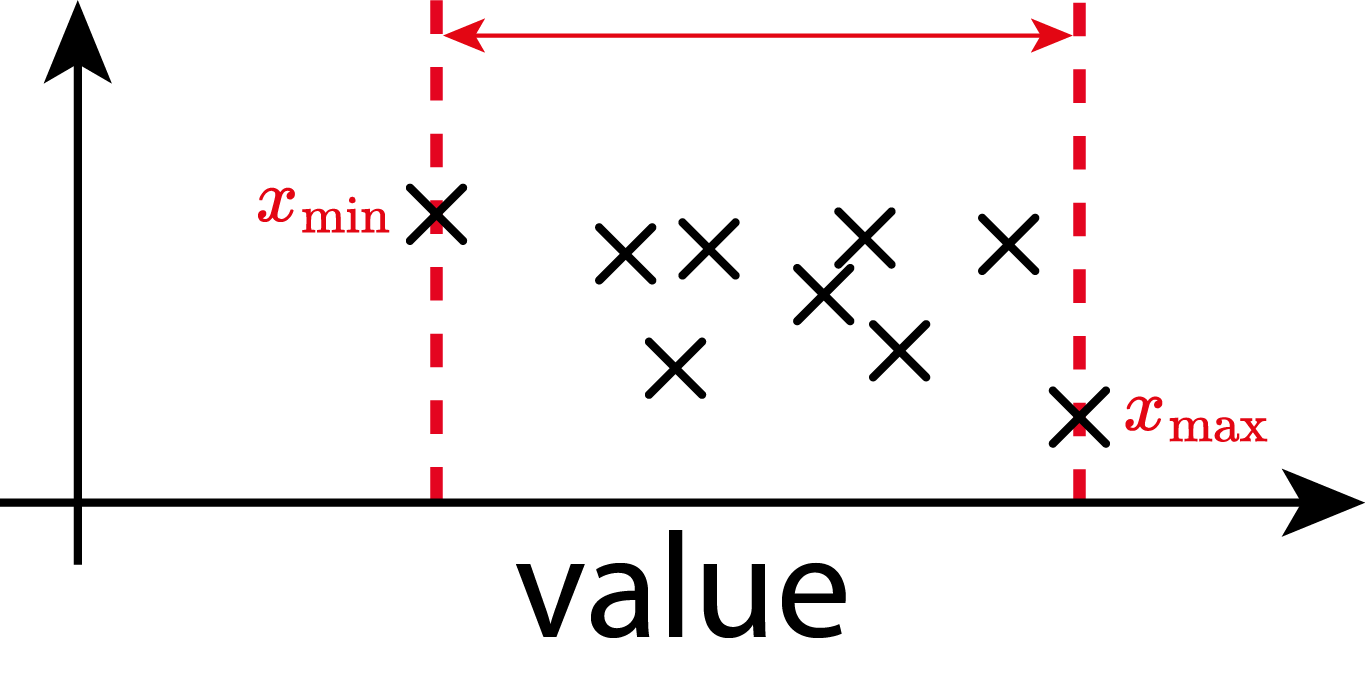
\[\begin{align} \text{Range} = x_{\text{max}} - x_{\text{min}} \end{align}\]
There is no difference in computing the range for the population or the sample
1.6.3.2 Variance
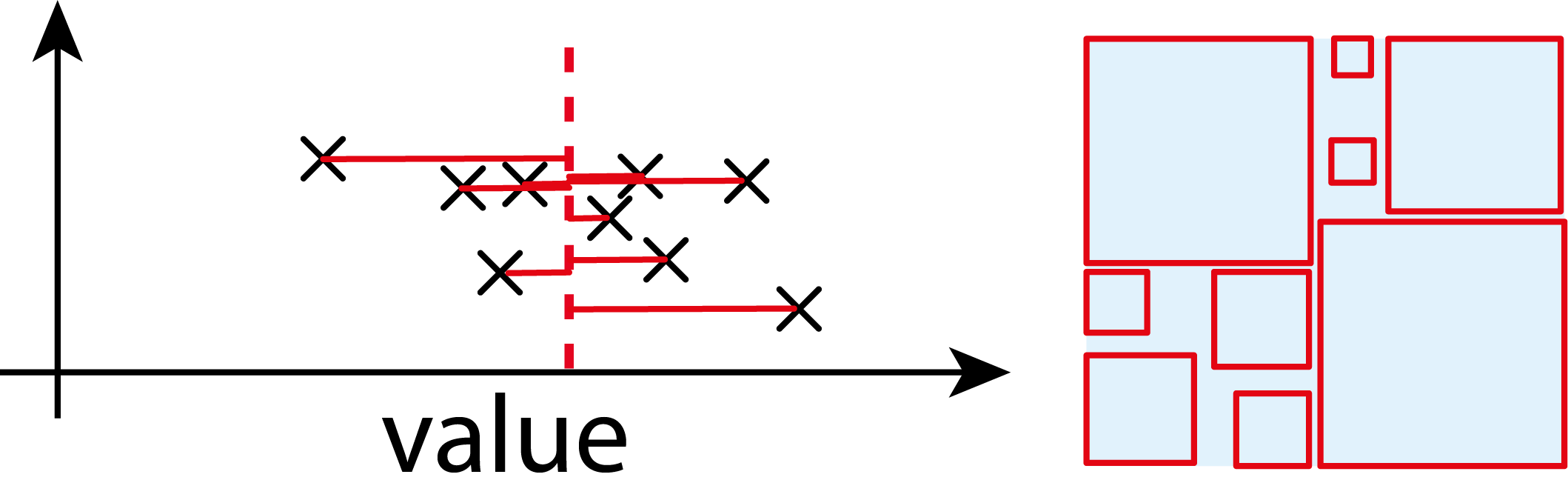
For a random variable \(X\) with mean \(\mu=\mathbb{E}\!(X)\):
\[\begin{align} \mathrm{Var}(X) &= \mathbb{E}\!\big[(X - \mu)^2\big] \label{var} \\ \mathrm{Var}(X) &= \mathbb{E}[X^2] - \big(\mathbb{E}[X]\big)^2 \end{align}\]
It is the expected squared deviation from the mean.
Always non-negative.
Units: square of the units of \(X\)
1.6.3.3 Standad Deviation
\[\begin{align} \sigma_0 &= \sqrt{\mathrm{Var}} \end{align}\]
\[\begin{align} \text{population: } \sigma &= \sqrt{\frac{1}{N} \sum_{i=1}^{N} (x_i - \mu)^2}\\ \text{sample: } sd &= \sqrt{\frac{1}{n-1} \sum_{i=1}^{n} (x_i - \bar{x})^2} \end{align}\]

1.6.3.3.1 The Bessel’s correction
The variance calculated from a sample has one degree of freedom (dof) less, then the population variance.
Imagine you have 5 candies, and you want to give them to 5 friends — one candy to each. You decide how to give the first candy, then the second, third, and fourth. But when you get to the last candy, you have no choice — you have to give it to the last friend, so everyone gets one.
That’s kind of like degrees of freedom in statistics. It means how many things you’re free to choose before something has to be a certain way.
So if you’re working with 5 numbers, and they all have to add up to a certain total (like a mean), you can choose 4 of them freely, but the last one has to be whatever makes the total come out right. That’s why we say there are 4 degrees of freedom — 4 numbers you can choose any way you want.
\[\{2,4,6\}\]
- Mean: \(\bar{x} = \frac{2+4+6}{3} = 4\)
- Deviations: \(-2,0,2\)
- Squared Deviations: \(4,0,4\)
- Sum of squared deviations: \(8\)
with Bessel’s correction: \(sd^2 = \frac{8}{3-1} = 4\)
without Bessel’s correction: \(sd^2 = \frac{8}{3} \approx 2.67\) (biased, underestimates variance)
When computing the variance from a sample, we need to calculate \(\bar{x}\), which uses up one degree of freedom and biases our estimate
1.6.3.3.2 Bessel’s correction with increasing sample size
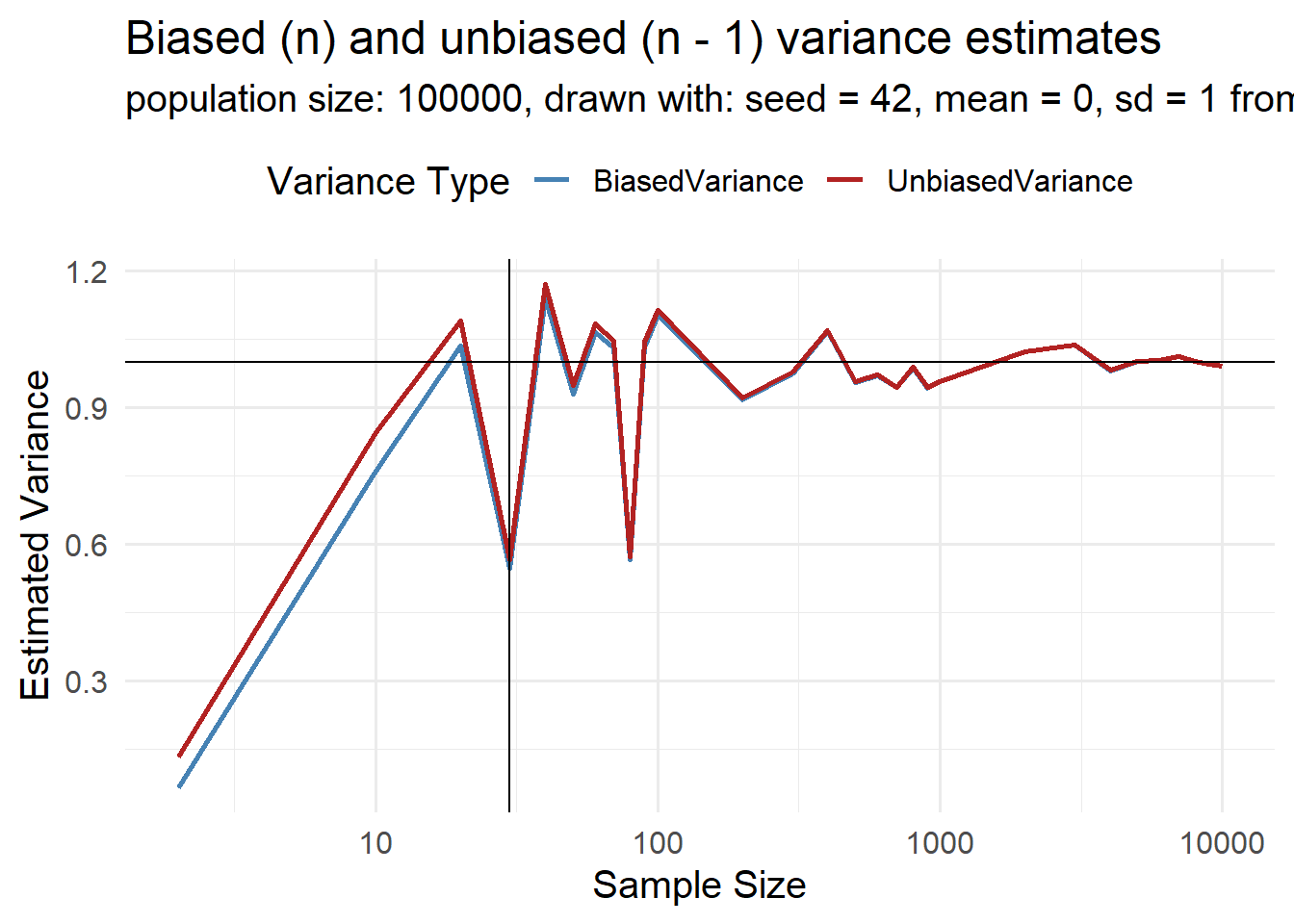
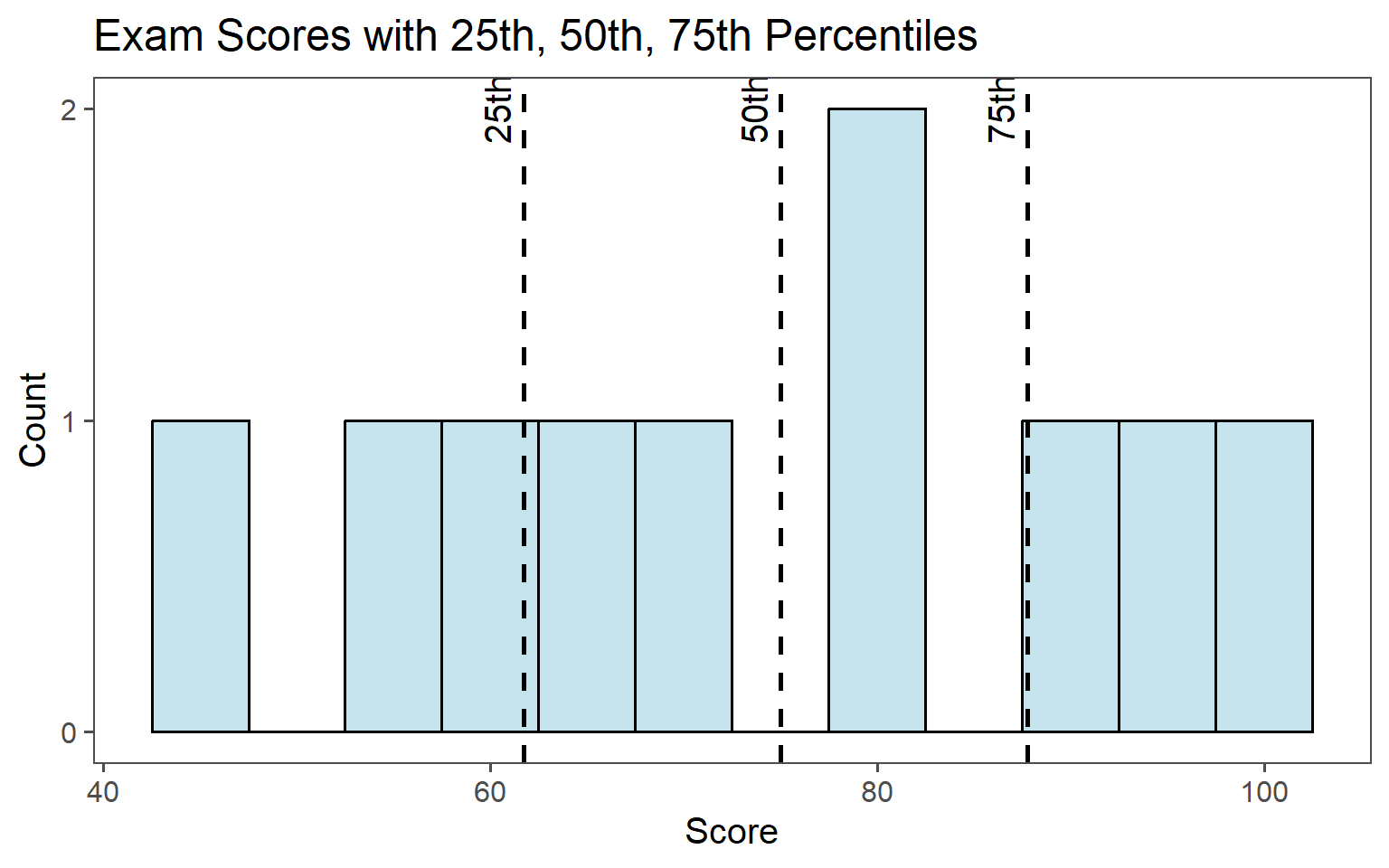
1.6.3.4 Percentiles, quantiles
Percentiles: Divide data into \(100\) equal parts. The \(p\)th percentile is the value below which p% of the observations fall.
Quantiles: Generalization of percentiles. The q-th quantile is the value below which a fraction q of the data falls. For example:
\(0.25\) quantile: \(25\)th percentile - first quartile (Q1)
\(0.50\) quantile: \(50\)th percentile - median
\(0.75\) quantile: \(75\)th percentile - third quartile (Q3)
1.6.4 Histogram
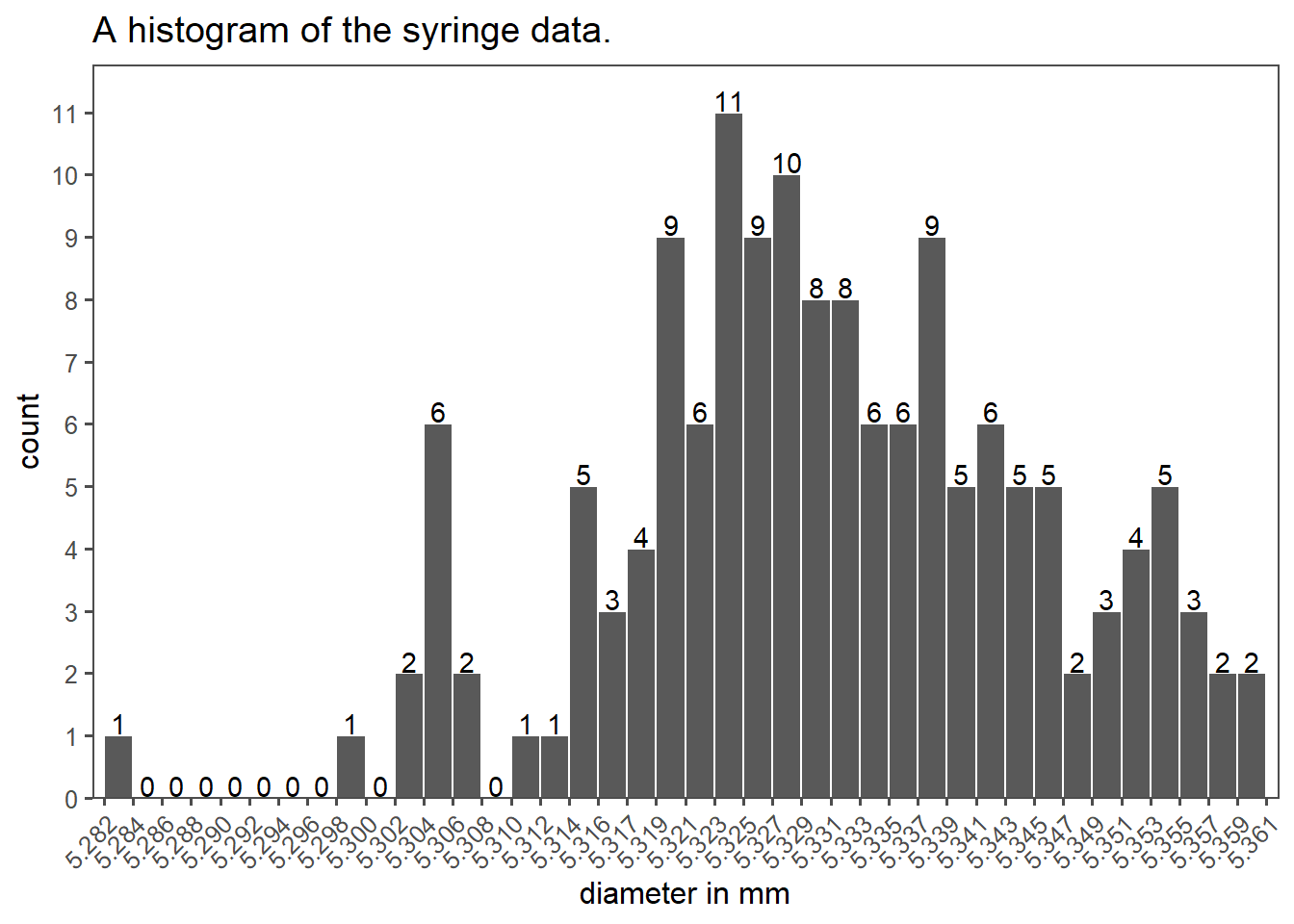
An example for descriptive statistics is shown in Figure 1.17 as a histogram. It shows data from a company that produces pharmaceutical syringes, taken from Ramalho (2021). During the production of those syringes, the so called barrel diameter is a critical parameter to the function of the syringe and therefore of special interest for the Quality Control.
A histogram as shown in Figure 1.17 shows the data of 150 measurements during the QC. On the x-axis the barrel diameter is shown, while the count of each binned diameter is shown on the y-axis. The binning and of data is a crucial parameter for such a plot, because it already changes the appearance and width of the bars. Binning is a trade-off between visibility and readability.
1.6.5 Density plot
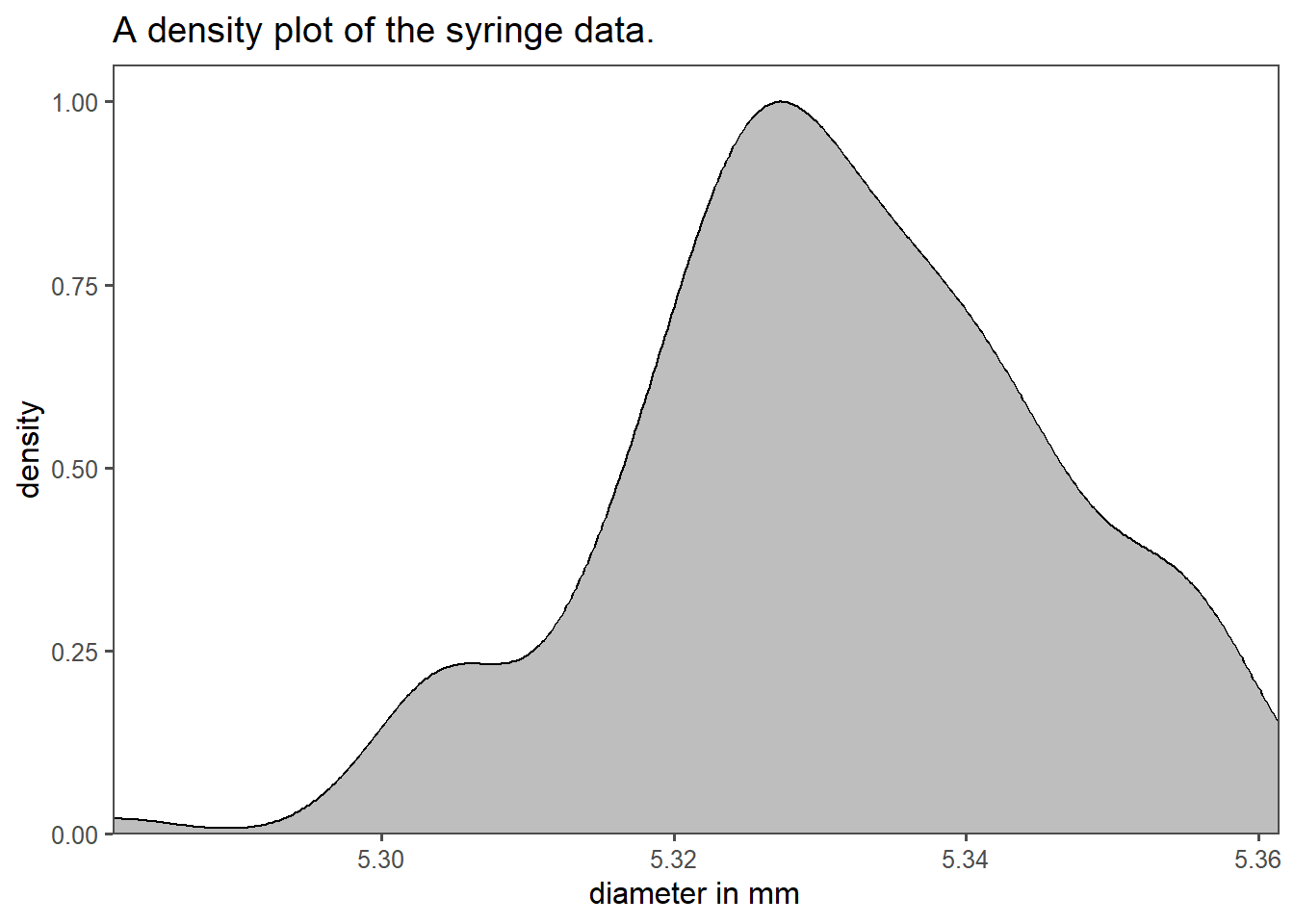
Density plots are another way of displaying the statistical distribution of an underlying dataset. The biggest strength of those plots is, that no binning is necessary in order to show the data. The limitation of this kind of plot is the interpretability. An example of a density plot for the syringe data is shown in Figure 1.18. On the x-axis the syringe barrel diameter is shown (as in a histogram). The y-axis in contrast does not display the count of a binned category, but rather the Probability Density Function (PDF) for the specific diameter. The grey area under the density curve depicts the probability of a syringe diameter to appear in the data. The complete area under the curve equals to \(1\) meaning that a certain diameter is sure to appear in the data.
1.6.6 Boxplot
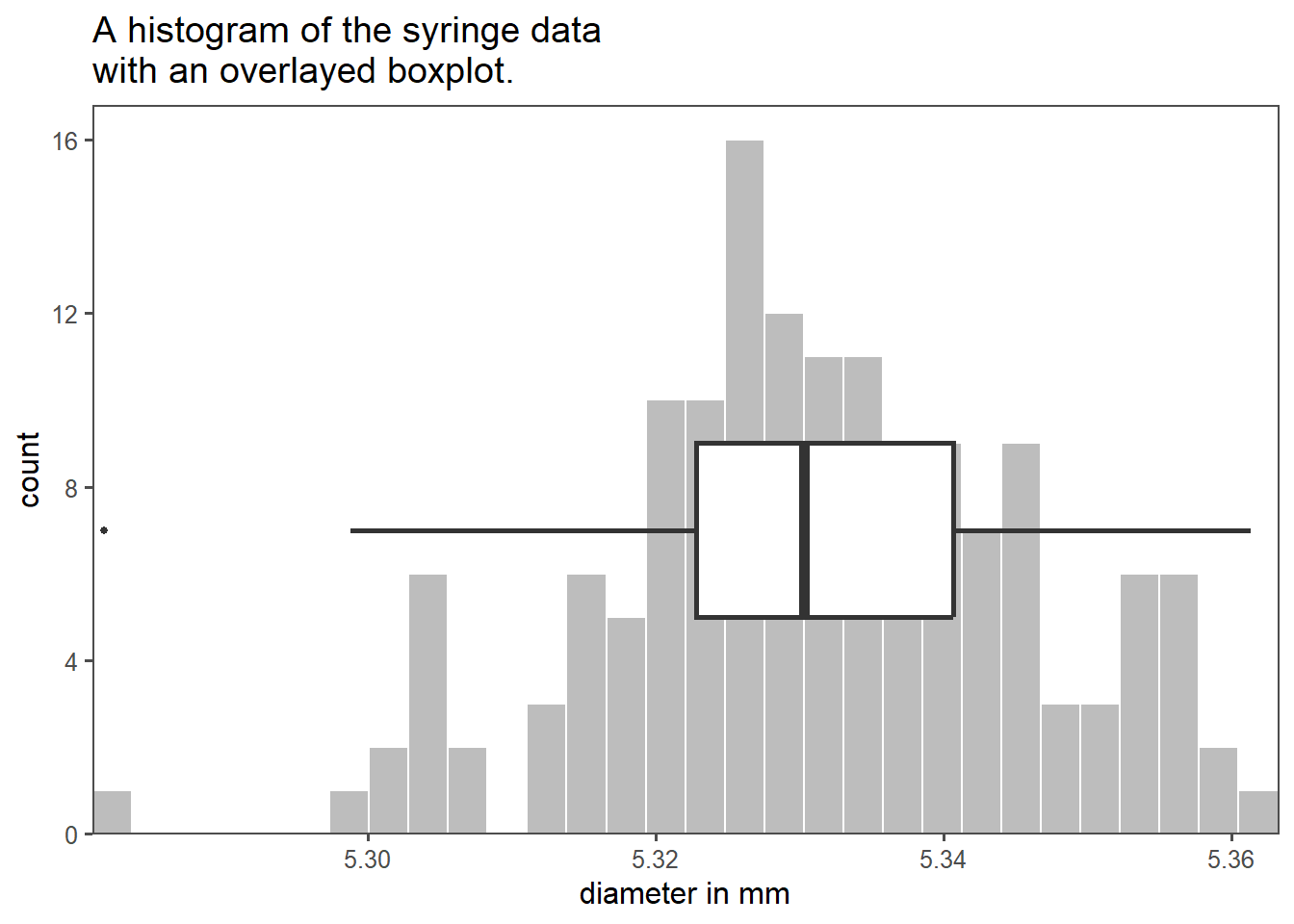
It is very common to include and inspect measures of central tendency in the graphical depiction of data. A boxplot, also known as a box-and-whisker plot, is a very common way of doing this. A boxplot is a graphical representation of a dataset’s distribution. It displays the following key statistics:
- Median (middle value).
- Quartiles (\(25^{th}\) and \(75^{th}\) percentiles), forming a box.
- Minimum and maximum values (whiskers).
- Outliers (data points significantly different from the rest).
The syringe data in boxplot form is shown in Figure 1.19 as an overlay of the histogram plot before. Boxplots are useful for quickly understanding the central tendency, spread, and presence of outliers in a dataset, making them a valuable tool in data analysis and visualization.
1.6.7 Average, Standard deviation and Range

Very popular measures of central tendency include the average (mean) and the standard deviation (variance) of a dataset. The computed mean from an actual dataset is depicted with \(\bar{x}\) and calculated via \(\eqref{mean}\).
\[\begin{align} \bar{x} = \frac{1}{n}\sum_{i=1}^{n} x_i \label{mean} \end{align}\]
With [\(n\)]{index.qmd#n-gloss} being the number of datapoints and \(x_i\) being the datapoints. The mean is therefore the sum of all datapoints divided by the total number \(n\) of all datapoints. It is not to be confused with the true mean \(\mu_0\) of a population.
The computed standard deviation from an actual dataset is depicted with [\(sd\)]{index.qmd#sd-gloss} and calculated via \(\eqref{sd}\).
\[\begin{align} sd = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (x_i - \bar{x})^2} \label{sd} \end{align}\]
The standard deviation can therefore be explained as the square root of the sum of all differences of each individual datapoints to the mean of a dataset divided by the number of datapoints. It is not to be confused with the true variance \(\sigma_0^2\) of a population. The variance of a dataset can be calculated via \(\eqref{var2}\).
\[\begin{align} \sigma = sd^2 \label{var2} \end{align}\]
The range from an actual dataset is depicted with \(r\) and calculated via \(\eqref{range}\).
\[\begin{align} r = \max(x_i) - \min(x_i) \label{range} \end{align}\]
The range can therefore be interpreted as the range from minimum to maximum in a dataset.
1.7 Visualizing Groups
1.7.1 Boxplots
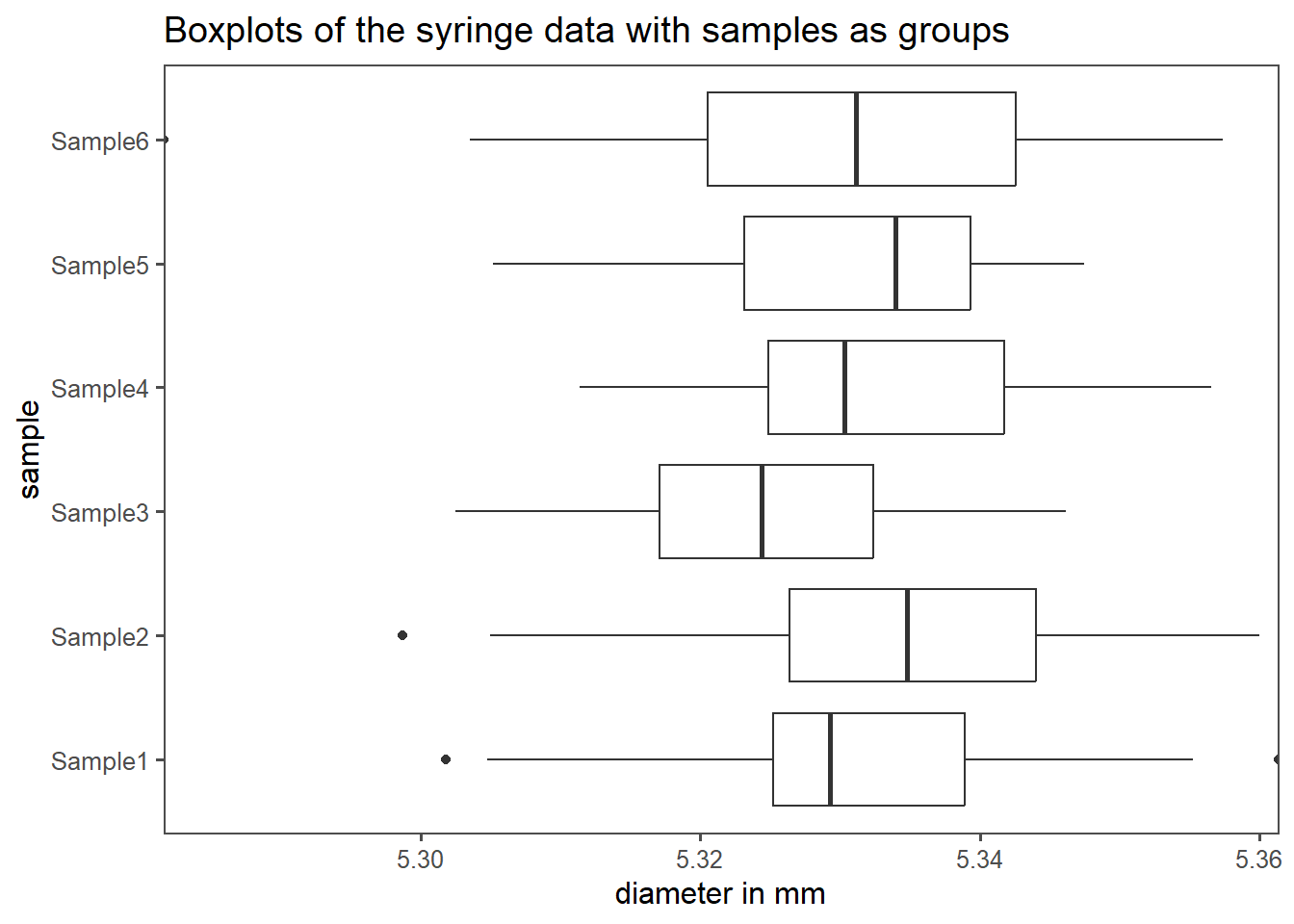
The methods described above are especially useful when it comes to visualizing groups in data. The data is discretized and the information density is increased. As with every discretization comes also a loss of information. It is therefore strongly advised to choose the right tool for the job.
If the underlying distribution of the data is unknown, a good start to visualize groups within data is usually a boxplot as shown in Figure 1.21. The syringe data from Ramalho (2021) contains six different groups, one for every sample drawn. Each sample consists of 25 observations in total. On the x-axis the diameter in mm is shown, the y-axis depicts the sample number. The boxplots are then drawn as described above (median, \(25^{th}\) and \(75^{th}\) percentile box, \(5^{th}\) and \(95^{th}\) whisker). The \(25^{th}\) and \(75^{th}\) percentile box is also known as the Interquartile Range (IQR).
1.7.2 Mean and standard deviation plots
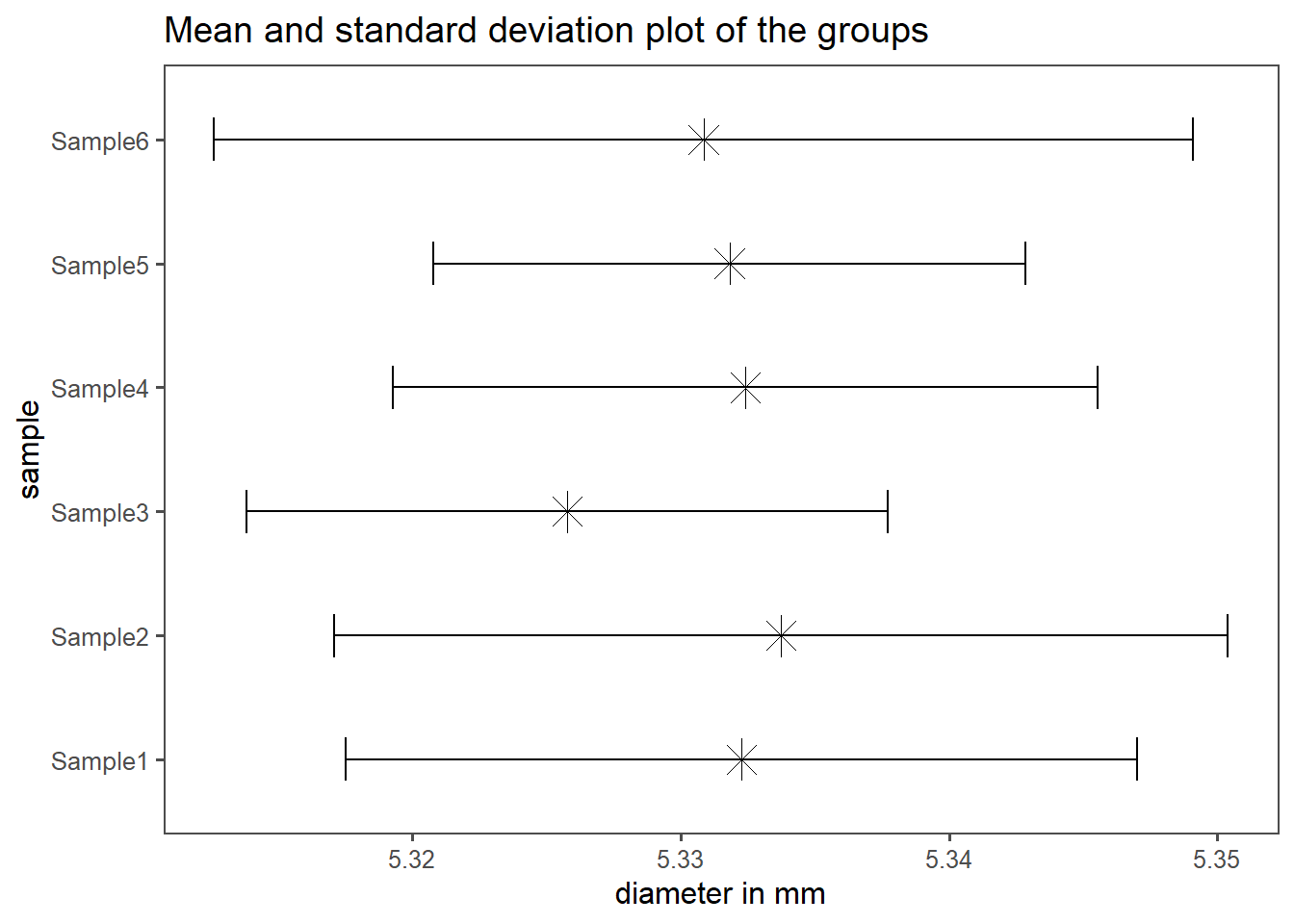
If the data follows a normal distribution, showing the mean and standard deviation for each group is also very common. For the syringe dataset, this is shown in Figure 1.22. The plot follows the same logic as for the boxplots (x-axis-data, y-axis-data), but the data itself shows the mean with a \(\times\)-symbol, as the length of the horizontal errorbars accords to \(\bar{x} \pm sd(x)\).
1.7.3 Half-half plots
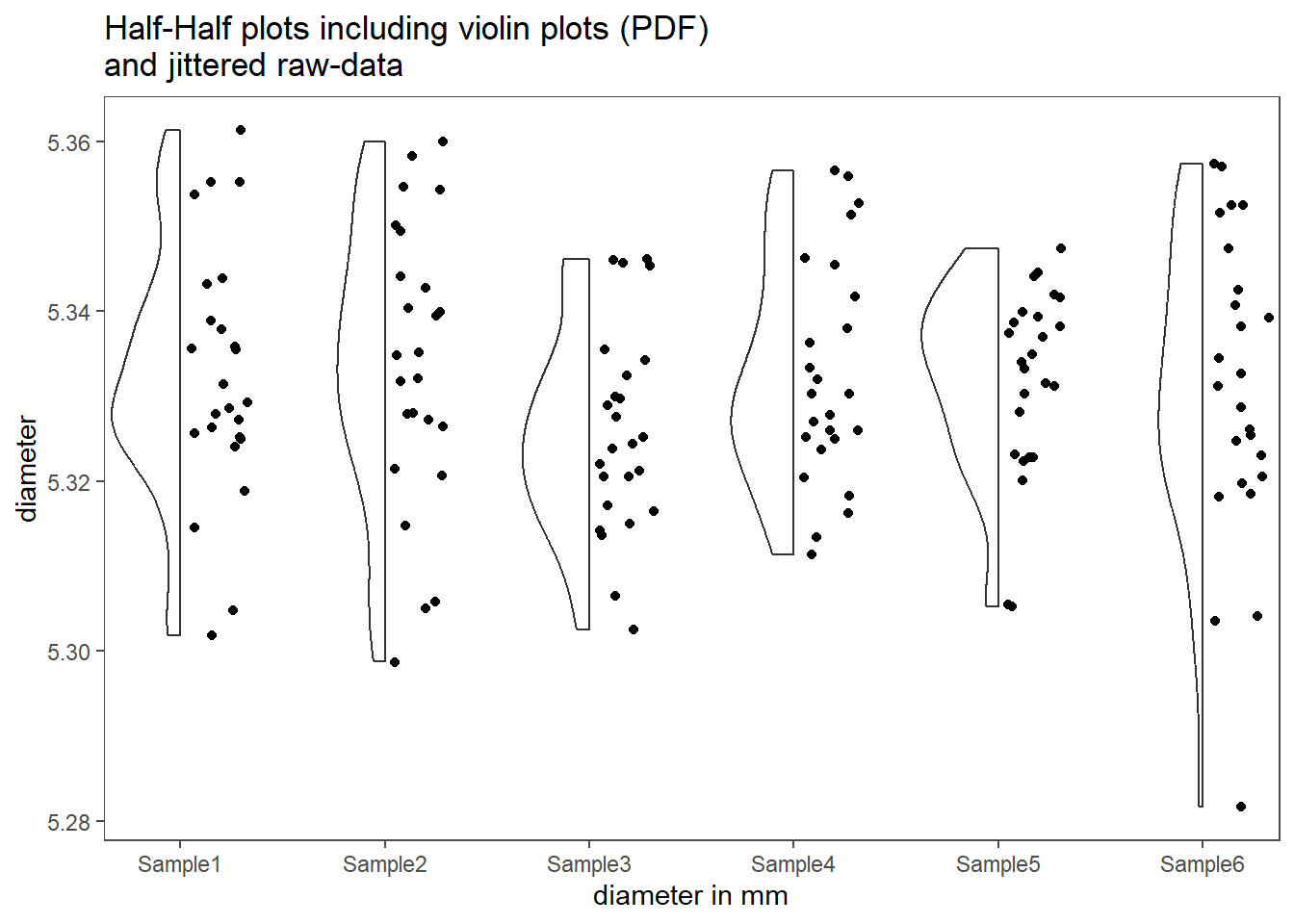
Boxplots and mean-and-standard-deviation plots sometimes hide some details within the data, that may be of interest or simply important. Half-half plots, as shown in shown in Figure 1.23, incorporate different plot mechanisms. The left half shows a violin plot, which outlines the underlying distribution of the data using the PDF. This is very similar to a density plot. The right half shows the original data points and give the user a visible clue about the sample size in the data size. Note that the y-position of the points is jittered to counter overplotting. Details can be found in Tiedemann (2022).
1.7.4 Ridgeline plots
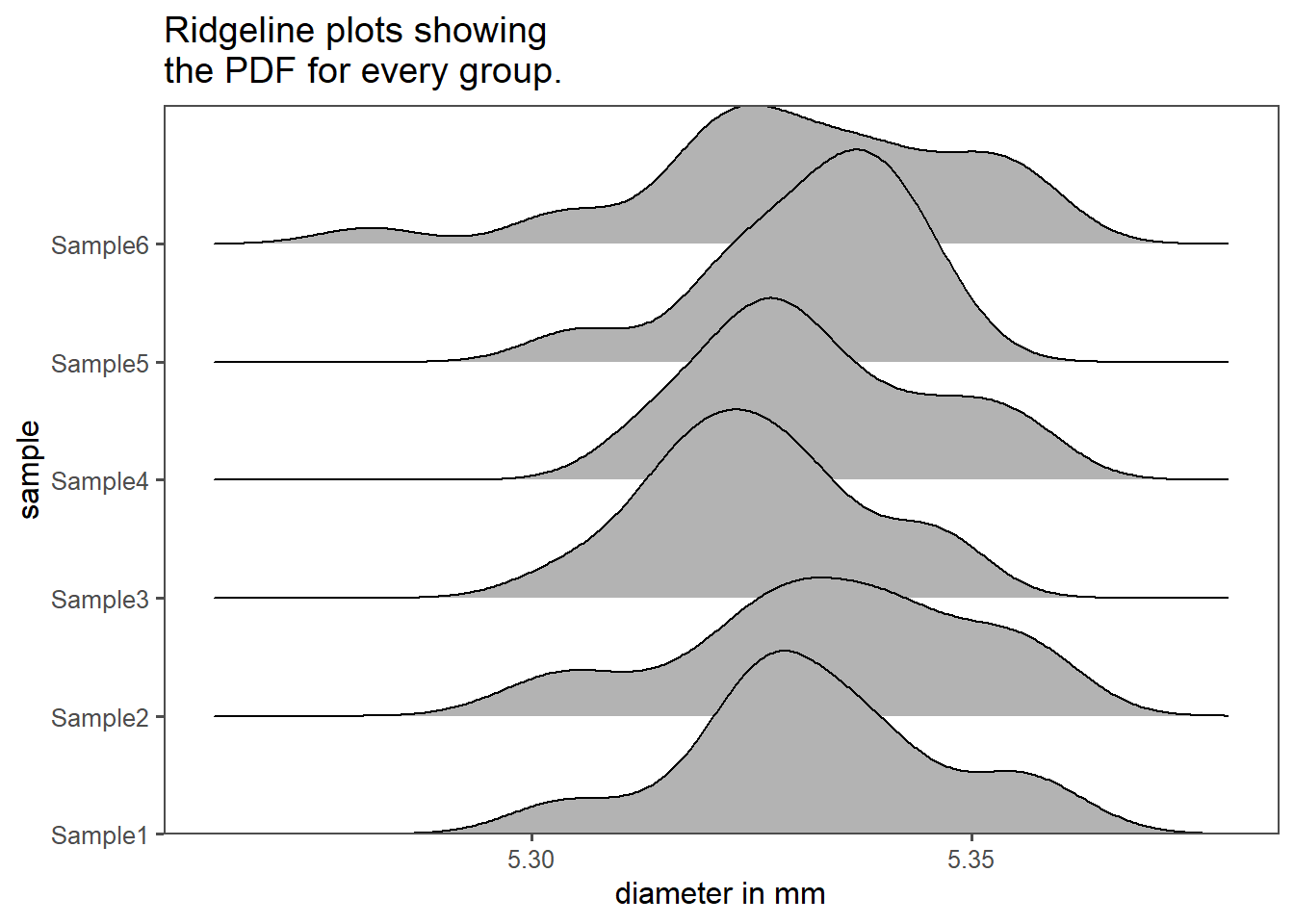
Figure 1.24 shows so called ridgeline plots as explained in Wilke (2022). They are in essence density plots that use the y-axis to differentiate between the groups. On the x-axis the density of the underlying dataset is shown. More info on the creation of these plots and graphics is available in Wickham (2016) as well as “The R Graph Gallery – Help and Inspiration for r Charts” (2022).
1.8 The drive shaft exercise
1.8.1 Introduction
A drive shaft is a mechanical component used in various vehicles and machinery to transmit rotational power or torque from an engine or motor to the wheels or other driven components. It serves as a linkage between the power source and the driven part, allowing the transfer of energy to propel the vehicle or operate the machinery.
Material Selection: Quality steel or aluminum alloys are chosen based on the specific application and requirements.
Cutting and Machining: The selected material is cut and machined to achieve the desired shape and size. Precision machining is crucial for balance and performance.
Welding or Assembly: Multiple sections may be welded or assembled to achieve the required length. Proper welding techniques are used to maintain structural integrity.
Balancing: Balancing is critical to minimize vibrations and ensure smooth operation. Counterweights are added or mass distribution is adjusted.
Surface Treatment: Drive shafts are often coated or treated for corrosion resistance and durability. Common treatments include painting, plating, or applying protective coatings.
Quality Control: Rigorous quality control measures are employed to meet specific standards and tolerances. This includes dimensional checks, material testing, and defect inspections.
Packaging and Distribution: Once quality control is passed, drive shafts are packaged and prepared for distribution to manufacturers of vehicles or machinery.
The end diameter of a drive shaft is primarily determined by its torque capacity, length, and material selection. It needs to be designed to handle the maximum torque while maintaining structural integrity and flexibility as required by the specific application. For efficient load transfer, there are ball bearings mounted on the end diameter. Ball bearings at the end diameter of a drive shaft support its rotation, reducing friction. They handle axial and radial loads, need lubrication for longevity, and may include seals for protection. Proper alignment and maintenance are crucial for their performance and customization is possible to match specific requirements.
The end diameter of the drive shaft shall be \(\varnothing 12\pm0.1mm\) (see Figure 1.25). This example will haunt us the rest of this lecture.
1.8.2 Visualizing all the Data
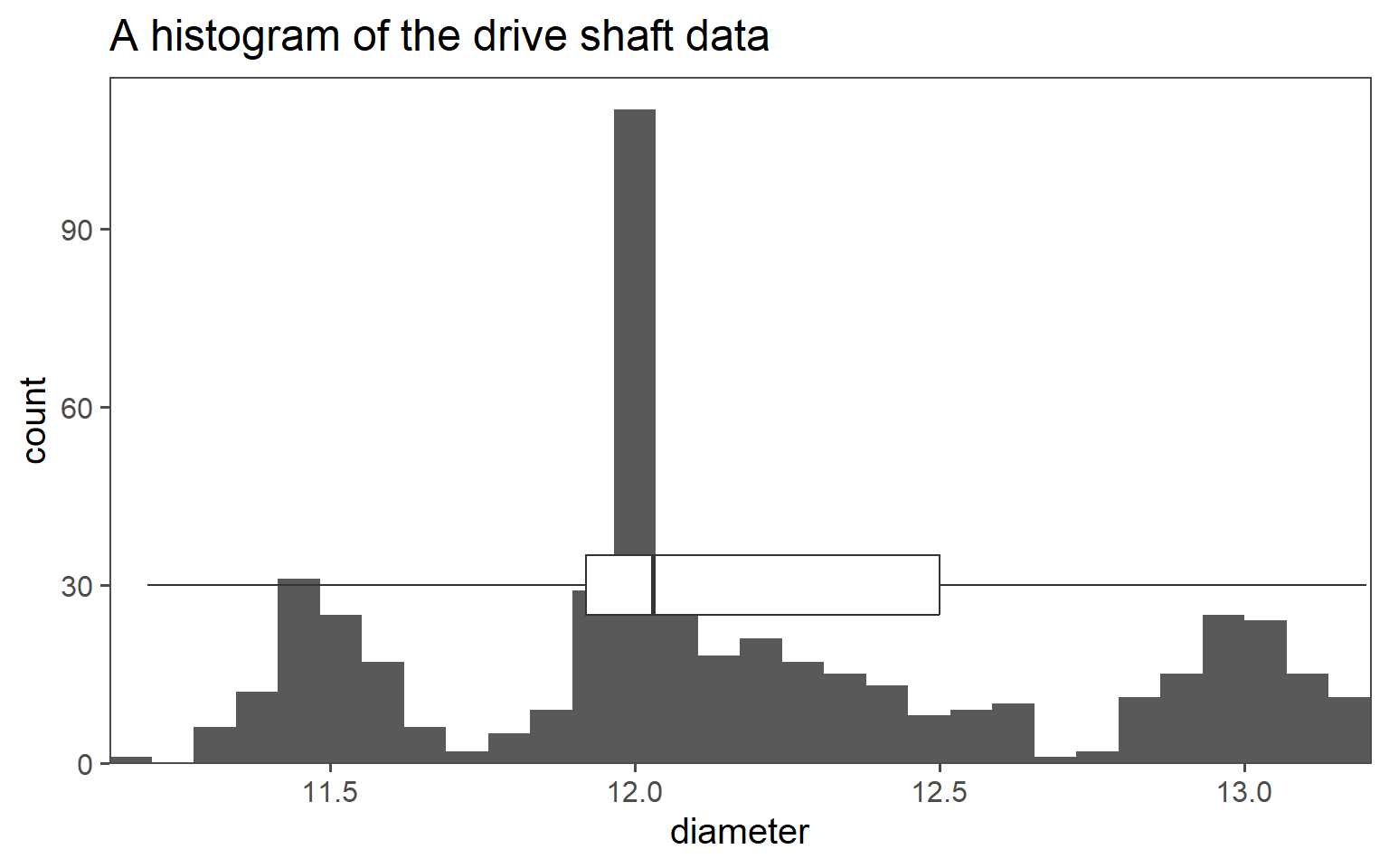
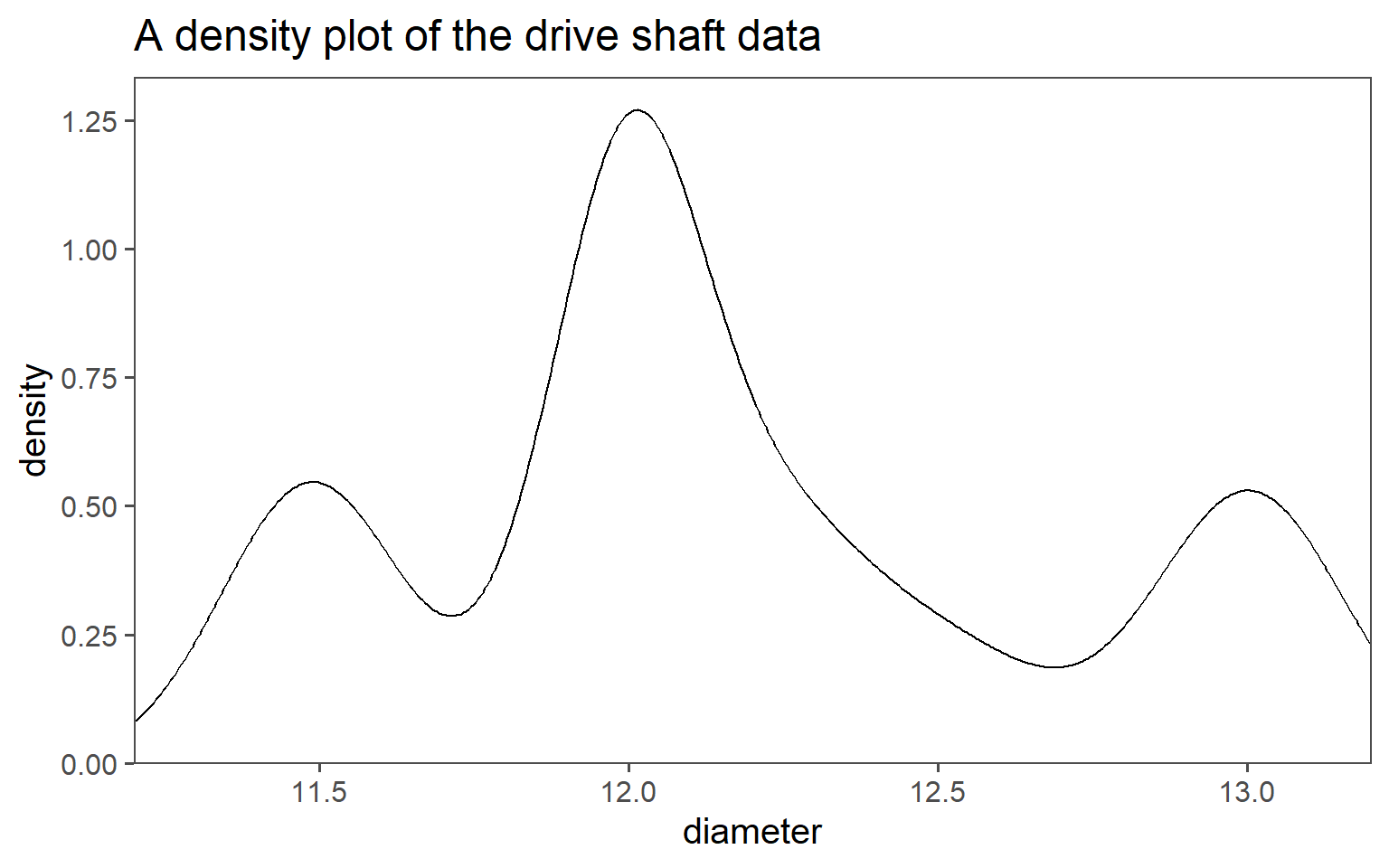
First, some descriptive statistics of \(N=500\) produced drive shafts are shown in Table 1.1 (\(\bar{x}(sd), median(IQR)\)). This first table does not tell us an awful lot about the sample, apart from the classic statistical measures of central tendency and spread.
| Variable | N = 5001 |
|---|---|
| diameter | 12.17 (0.51), 12.03 (0.58) |
| 1 Mean (SD), Median (IQR) | |
In Figure 1.26 the data and the distribution thereof is visualized using different modalities. The complete drive shaft data is shown as a histogram (Figure 1.26 (a)) and as a density plot (Figure 1.26 (b)). A single boxplot is plotted over the histogram data in Figure 1.26 (a), providing a link to Table 1.1 (median and IQR). One important conclusion may be draw from those plots already: There may be more than one dataset hidden inside the data. We will explore this possibility further.
1.8.3 Visualizing groups within the data
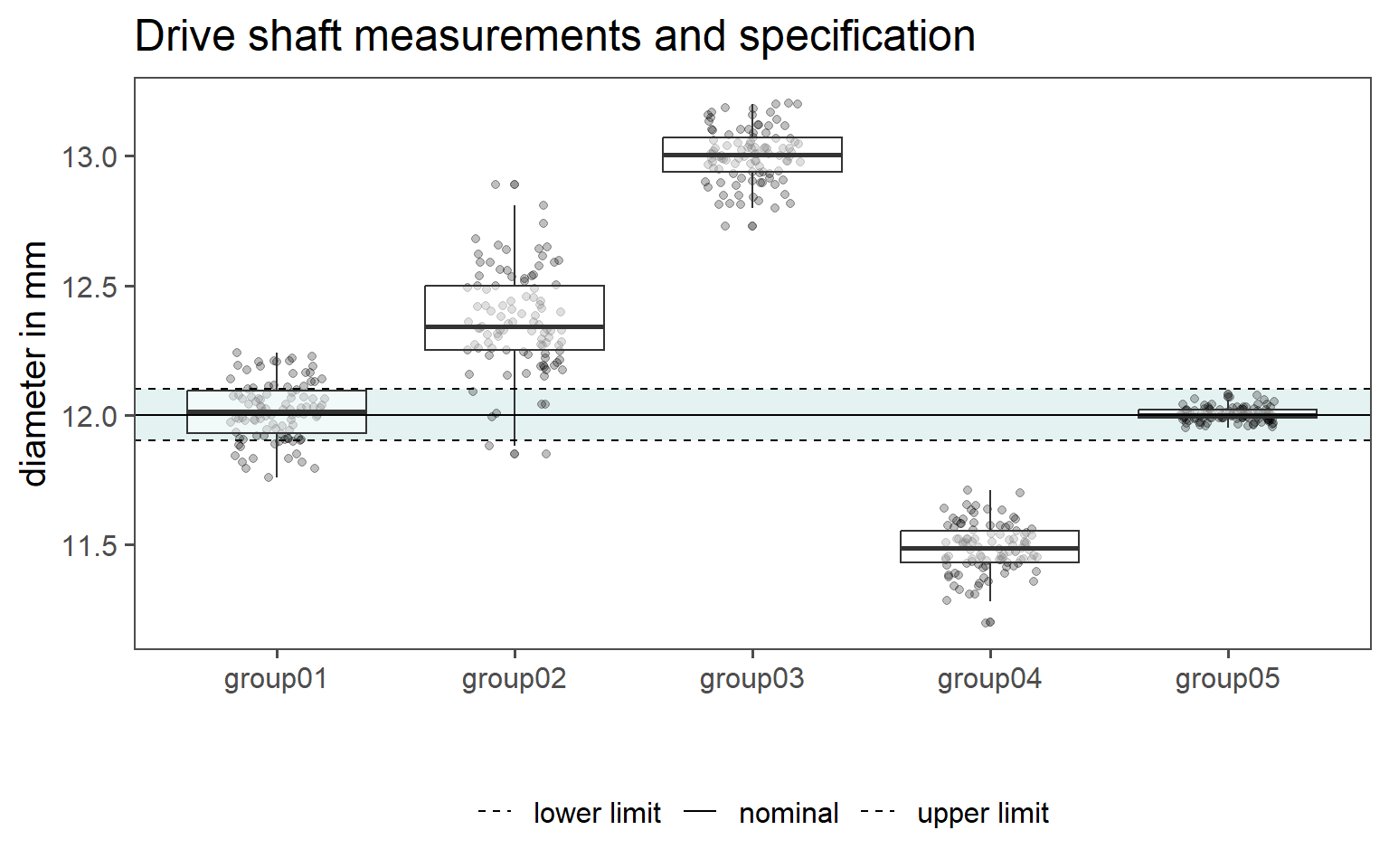
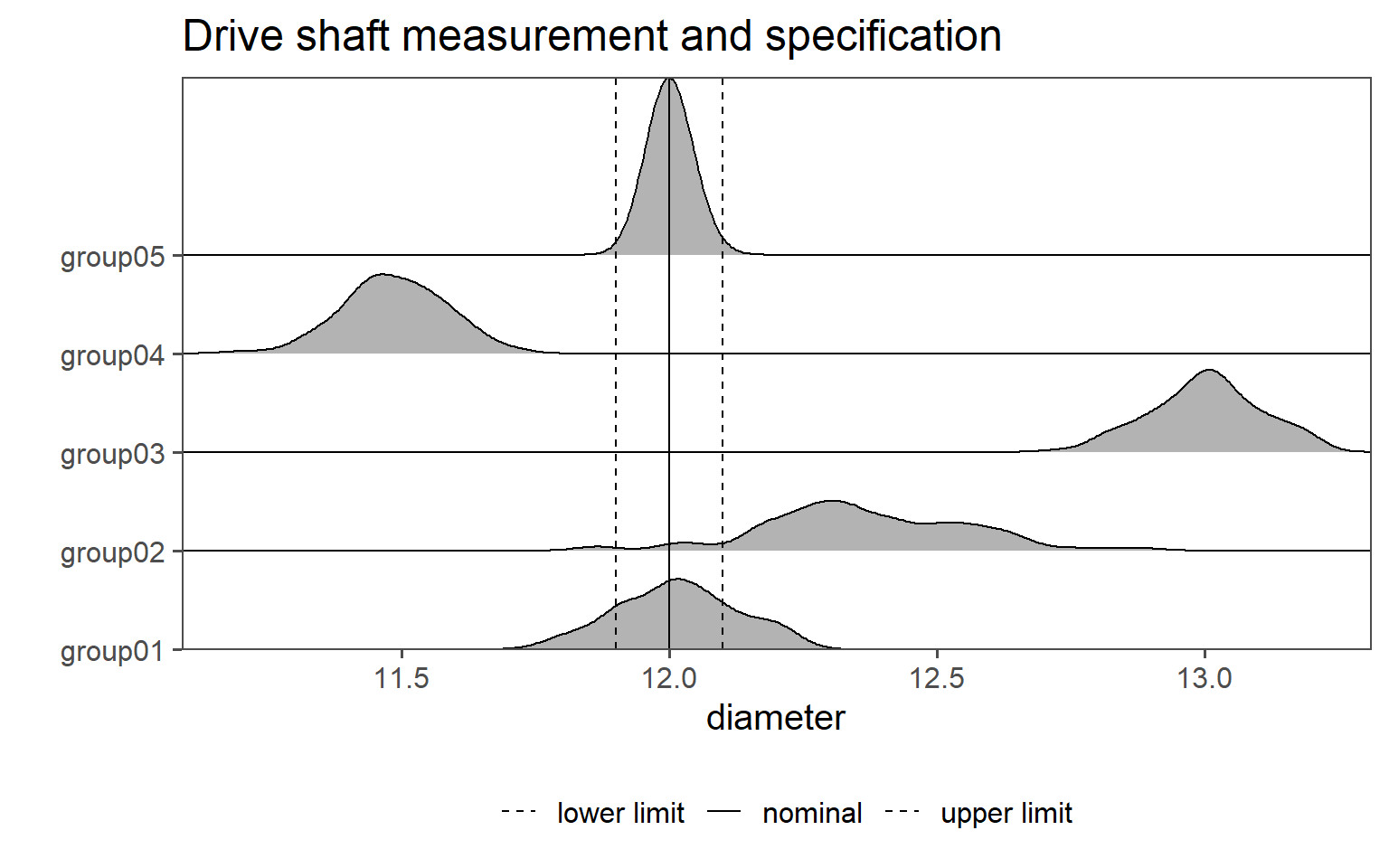
Fortunately for us, the groups that may be hidden within the data are marked in the orginal dataset and denoted as group0x. Unfortunately for us, it is not known (purely from the data) how these groups come about. Because we did get the dataset from a colleague, we need to investigate the creation of the dataset even further. This is an important point, for without knowledge about the history of the data, it is impossible or at least unadvisable to make valid statements about the data. We will go on with a table of summary statistics, see Table 1.2. Surprisingly, there are five groups hidden within the data, something we would no be able to spot from the raw data alone.
| Variable | N = 1001 |
|---|---|
| group01 | 12.02 (0.11), 12.02 (0.16) |
| group02 | 12.36 (0.19), 12.34 (0.25) |
| group03 | 13.00 (0.10), 13.01 (0.13) |
| group04 | 11.49 (0.09), 11.49 (0.12) |
| group05 | 12.001 (0.026), 12.000 (0.030) |
| 1 Mean (SD), Median (IQR) | |
Again, the table is good to have, but not as engagingi for ourself and our co-workers to look at. In order to make the data more approachable, we will use some techniques shown in Section 1.7.
First in Figure 1.27 (a) the raw data points are shown as points with overlayed boxplots. On the x-axis the groups are depicted, while the Parameter of Interest (PoI) (in this case the end diameter of the drive shaft) is shown on the y-axis. Because we are interested how the manufactured drive shafts behave with respect to (wrt) the specification limit, the nominal value as well as the uppper and the lower specification limit is also shown in the plot as horizontal lines.
In Figure 1.27 (b) the data is shown as ridgeline density plots. On the x-axis the diameter is depiected, while the y-axis shows two types of data. First, the groups \(1\ldots5\) are shown. For the individual groups, the probability is depicted as a line, therefore indicating which values are most probable in the given group. Again, because we are interested how the manufactured drive shafts behave .w.r.t the specification limit, the nominal value as well as the uppper and the lower specification limit is also shown in the plot as vertical lines.
Bartlett, Maurice Stevenson. 1937. “Properties of Sufficiency and
Statistical Tests.” Proceedings of the Royal Society of
London. Series A - Mathematical and Physical Sciences 160 (901):
268–82. https://doi.org/10.1098/rspa.1937.0109.
Bonferroni, C. E. 1936. Teoria Statistica Delle Classi e Calcolo
Delle Probabilità. Pubblicazioni Del r. Istituto
Superiore Di Scienze Economiche e Commerciali Di Firenze. Seeber. https://books.google.de/books?id=3CY-HQAACAAJ.
Cano, Emilio L., Javier M. Moguerza, and Andrés Redchuk. 2012.
“Six Sigma with r” Not available: Not available. https://doi.org/10.1007/978-1-4614-3652-2.
Champely, Stephane. 2020. Pwr: Basic Functions for Power
Analysis. https://CRAN.R-project.org/package=pwr.
Davies, Rhian, Steph Locke, and Lucy D’Agostino McGowan. 2022.
datasauRus: Datasets from the Datasaurus Dozen. https://CRAN.R-project.org/package=datasauRus.
Delignette-Muller, Marie Laure, and Christophe Dutang. 2015.
“fitdistrplus: An R
Package for Fitting Distributions.” Journal of Statistical
Software 64 (4): 1–34. https://doi.org/10.18637/jss.v064.i04.
Friedman, Milton. 1937. “The Use of Ranks to Avoid the Assumption
of Normality Implicit in the Analysis of Variance.” Journal
of the American Statistical Association 32 (December): 675–701. https://doi.org/10.1080/01621459.1937.10503522.
Greenhouse, Samuel W., and Seymour Geisser. 1959. “On Methods in
the Analysis of Profile Data.” Psychometrika 24 (June):
95–112. https://doi.org/10.1007/bf02289823.
Grömping, Ulrike. 2014. “RPackageFrF2for Creating and Analyzing
Fractional Factorial 2-Level Designs.” Journal of Statistical
Software 56 (1). https://doi.org/10.18637/jss.v056.i01.
Hahs-Vaughn, Debbie L., and Richard G. Lomax. 2013. An Introduction
to Statistical Concepts. Routledge. https://doi.org/10.4324/9780203137819.
Ioannidis, John P. A. 2005. “Why Most Published Research Findings
Are False.” PLoS Medicine 2 (8): e124. https://doi.org/10.1371/journal.pmed.0020124.
Ismay, Chester, and Albert Y. Kim. 2019. Statistical Inference via
Data Science. Chapman & Hall/CRC: The R Series.
J. Bibby, E. J. G. Pitman. 1980. “Some Basic Theory for
Statistical Inference.” The Mathematical Gazette 64
(428): 138–38. https://doi.org/10.2307/3615104.
Johnson, Norman Lloyd. 1994. Continuous Univariate
Distributions. Wiley.
Lienig, Jens, and Hans Bruemmer. 2017. “Fundamentals of Electronic
Systems Design” Not available: Not available. https://doi.org/10.1007/978-3-319-55840-0.
Mann, H. B., and D. R. Whitney. 1947. “On a Test of Whether One of
Two Random Variables Is Stochastically Larger Than the Other.”
The Annals of Mathematical Statistics. https://doi.org/10.1214/aoms/1177730491.
Mauchly, John W. 1940. “Significance Test for Sphericity of a
Normal n-Variate Distribution.” The Annals of Mathematical
Statistics 11 (2): 204–9. http://www.jstor.org/stable/2235878.
Meyna, Arno. 2023. Sicherheit Und Zuverlässigkeit Technischer
Systeme. Carl Hanser Verlag GmbH &
Co. KG. https://doi.org/10.3139/9783446468085.fm.
Nuzzo, Regina. 2014. “Scientific Method: Statistical
Errors.” Nature 506 (7487): 150–52. https://doi.org/10.1038/506150a.
Olkin, Ingram. June. Contributions to Probability and
Statistics. Stanford Univ Pr.
Pearson, Karl. 1895. “Note on Regression and Inheritance in the
Case of Two Parents.” Proceedings of the Royal Society of
London Series I 58: 240–42.
Ramalho, Joao. 2021. industRial: Data, Functions and Support
Materials from the Book "industRial Data Science". https://CRAN.R-project.org/package=industRial.
Ruder, Sebastian. 2016. “An Overview of Gradient Descent
Optimization Algorithms.” http://arxiv.org/pdf/1609.04747.pdf.
Shapiro, S. S., and M. B. Wilk. 1965. “An Analysis of Variance
Test for Normality (Complete Samples).” Biometrika 52
(December): 591–611. https://doi.org/10.1093/biomet/52.3-4.591.
Shewhart, Walter Andrew, and William Edwards Deming. 1986.
Statistical Method from the Viewpoint of Quality Control.
Courier Corporation.
Spearman, C. 1904. “The Proof and Measurement of Association
Between Two Things.” The American Journal of Psychology.
https://doi.org/10.2307/1412159.
Standards, National Institute of, Technology (U.S.), and International
SEMATECH. 2002. “NIST/SEMATECH Engineering Statistics
Handbook,” January. https://doi.org/10.18434/M32189.
Starmer, J. 2022. The StatQuest Illustrated Guide to Machine
Learning!!!: Master the Concepts, One Full-Color Picture at a Time, from
the Basics All the Way to Neural Networks. BAM! Packt Publishing,
Limited. https://books.google.de/books?id=gWRGzwEACAAJ.
Student. 1908. “The Probable Error of a Mean.”
Biometrika 6 (1): 1. https://doi.org/10.2307/2331554.
Taboga, Marco. 2017. Lectures on Probability Theory and Mathematical
Statistics - 3rd Edition. Createspace Independent Publishing
Platform.
Tamhane, Ajit C. 1977. “Multiple Comparisons in Model i One-Way
Anova with Unequal Variances.” Communications in Statistics -
Theory and Methods 6 (January): 15–32. https://doi.org/10.1080/03610927708827466.
“The R Graph Gallery – Help and Inspiration for r
Charts.” 2022. https://r-graph-gallery.com/.
Tiedemann, Frederik. 2022. Gghalves: Compose Half-Half Plots Using
Your Favourite Geoms. https://CRAN.R-project.org/package=gghalves.
Weibull, Waloddi. 1951. “A Statistical Distribution Function of
Wide Applicability.” Journal of Applied Mechanics 18
(3): 293–97. https://doi.org/10.1115/1.4010337.
WELCH, B. L. 1947. “The Generalization of "STUDENT’s" Problem When
Several Different Population Variances Are Involved.”
Biometrika. https://doi.org/10.1093/biomet/34.1-2.28.
Wickham, Hadley. 2016. Ggplot2: Elegant Graphics for Data
Analysis. Springer-Verlag New York. https://ggplot2.tidyverse.org.
Wickham, Hadley, and Garrett Grolemund. 2016. R for Data
Science. "O’Reilly Media, Inc.".
Wilke, Claus O. 2022. Ggridges: Ridgeline Plots in ’Ggplot2’.
https://CRAN.R-project.org/package=ggridges.
Sir Francis Galton (1822-1911): Influential English scientist, notable for his contributions to statistics and genetics.↩︎